
Will data served as language models overtake the role of semantic/linked data?
Semantic data was all about being self-sufficient. Do models do this better now?

I wrote before about how I think we need to go towards a world with fewer huge datasets laying around, and instead go towards serving data as models (think large language models such as ChatGPT, but smaller and more local) that can be continuously updated without complete re-computation.
One thing to note about what data served as models do, is they make data self-sufficient and self-describing. They allow to access the information in the model without knowing a lot of technical details about the data, such as a data schema.
Sure, you still need to know some of the human (or computer) languages used to encode the knowledge, but at least the interface is much more open to exploration and can provide answers even to very incomplete queries.
Semantic data, as known as Semantic Web or Linked data, ultimately had a similar goal: All data should be encoded in such a way that it is easily interpreteable without knowing a complex data schema in beforehand.
Now, the focus for sure was more on machine-readability than on human readability, although there were multiple efforts for providing more human friendly, explorative interfaces as well. Actually, our work on RDFIO, the Semantic Import/Export plugin for Semantic Mediawiki, was just such an effort, as we envisioned MediaWiki to be a perfect platform for both exploring and editing linked data.
I also wrote about how a tool with strong reasoning capabilities, such as Prolog, might be a great tool for integrating knowledge into a common, more high level and user friendly interface, using an image like the one below:
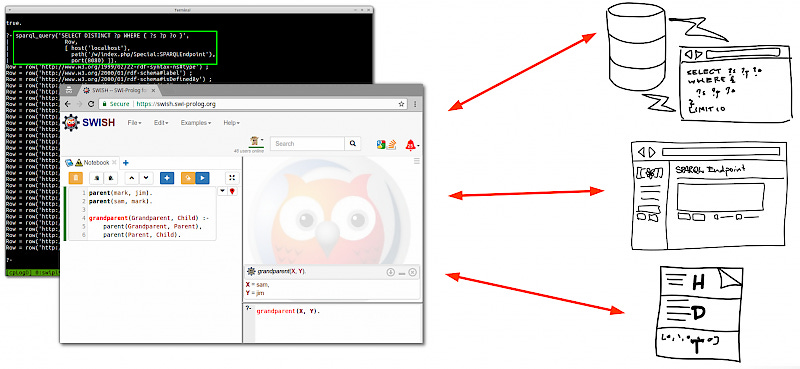
I still believe there is much opportunity to be had in this direction. But it also seems to take a lot of work, and there is not a strong community or ecosystem of tooling around this kind of thinking, so things don’t happen by themselves.
To me it seems large language models present an opportunity to fill in this role with a tool chain that is much more automated.
If we can just get less data- and resource-demanding tooling around the Language Models, that can be run locally without requiring data center-levels of storage, we could imagining starting to package datasets into a thin layer of language models that allows accessing the data in very flexible ways, without knowing the data schema in beforehand.
One has to ask though, who is going to ask these models for data. Humans are good at this, but if we want to envision computers accessing the data, we probably need to envision multiple language models talking to each other, since the language models often need some level of flexible exploration in order to achieve their goals.
But what format should they use for communicating? Here we come in to one field where I think the linked data technologies still can excel and find a niche:
They might very well be an optimal format for interchange of data between language models, since they are fully self-described, and are always linked to the relevant context.
In other words, it seems we could very well end up in a world with Language Models talking to each other via Linked Data? At least it seems like a promising opportunity, if someone wants to work on tools in that direction.
What are your thoughts?
Samuel